Muchos sitios web hacen uso de expertos en SEO (Search Engine Optimization) y SEM (Search Engine Marketing)
para posicionar correctamente las páginas web junto con los resultados
que les interesan. Esto es una dura tarea en varias áreas, pero
podríamos simplificarla con un "Salir lo más arriba en los resultados de un buscador en los términos que interese a la compañía", lo que parece muy evidente, pero también "Salir lo más abajo o no salir junto a los términos que no interese".
De este último caso, de borrarse de unos términos, son famosos los casos de la
SGAE y el término
Ladrones o el último y más sonado caso de
Urdangarín y
La Casa Real. En ambos casos se hizo uso del fichero
robots.txt para que los buscadores no indexaran contenido relativo a ambos términos en la web, tal y como puede verse hoy mismo en
SGAE y
Casa Real.
 |
| Figura 1: Fichero robots.txt de Casa Real |
En el caso de
SGAE, no solo han intentado borrar el término "
ladrones", sino otros como "
mafiosos" o algunos curiosos ataques aprovechando un bug de
XSS que ya en el año
2009 había sido
reportado desde Security By Default.
 |
| Figura 2: Fichero robots.txt de SGAE |
En el caso de Urdangarín, no fue solo la Casa Real
quién lo quitó de su web, sino más de una treintena de sitios
decidieron que el contenido que tenían dedicado a su persona ya no era
una buena tarjeta de presentación para los navegantes, así que lo han
quitado de la indexación de Google.
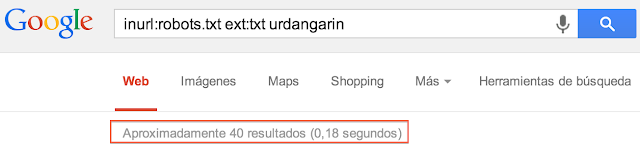 |
| Figura 3: 40 resultados de la cadena "urdangarin" en ficheros robots.txt |
Entre ellos hay algunos periódicos muy curiosos, con algunos contenidos
que aún están publicados, pero que han preferido quitar del "mainstream" del término en los buscadores. En la siguiente captura se puede ver como aparecen en todos los ficheros robots.txt con el término Disallow.
 |
| Figura 4: Sitios que han querido quitar su contenido sobre Urdangarín de Google |
Esto no solo ha pasado con Urdangarín. Por ejemplo, con el caso Barcenas,
muchos sitios han decidido que - tal vez - algunas opiniones y/o
contenido ya no tenían validez, y era mejor desaparecer del mapa, por lo
que había que intentar quitar el contenido de la base de datos de
indexación cuanto antes.
Esto si se hace así, podría ser debido a que el equipo de comunicaciones
de un entidad haya repartido contenido para ser publicado en varios
medios de información, queriendo conseguir una determinada corriente de
pensamiento y opinión, pero después - normalmente por un cambio en las
condicionantes - decide que esa comunicación ya no es buena y hay que
orquestar una retirada masiva del contenido.
 |
| Figura 5: Sitios web queriendo quitar su información sobre el Caso Barcenas |
En cualquier caso, esta opción de utilizar robots.txt para quitar el
contenido del buscador sigue siendo rudimentaria, visto lo visto, así
que lo mejor es que entren en las Herramientas del Webmaster, y eliminen
la URL de la base de datos del buscador y listo.
 |
| Figura 6: Eliminar una URL desde las herramientas del Webmaster |
Esto es una acto mucho más quirúrgico ya que elimina contenido,
URL y título, mientras que usar el fichero
robotst.txt solo garantiza la eliminación del contenido, y limpio, ya que no deja ningún rastro en el propio fichero
robots.txt que es más
verbose de lo que debería.
Fuente http://www.elladodelmal.com
De Chema Alonso






