En varias ocasiones he hablado por aquí del problema que tienen las opciones de indexación de
URLs tal y como se configuran el
Google que pueden llevar a fugas de datos y problemas de privacidad. Ejemplos de esto os he puesto con
Facebook,
WhatsApp y con
Gmail, pero el número de sitios que se ven afectados son infinitos, por lo que puedes pasarte una tarde divertida
dorking as a ninja a ver qué sale.
 |
| Figura 1: Fichero robots.txt de DropBox |
Un amigo por
Facebook -
¡Gracias Alan Brian! - en lugar de
pedirme que hackeara cosas para él, me avisó de que en
Dropbox sucede lo mismo y que el material que allí se puede encontrar es jugoso. Basta con irse a echar un ojo al
fichero robots.txt de DropBox para ver que todos los archvios que se encuentren en los directorios
/s y
/sh están prohibidos para su indexación, pero sin embargo las direcciones
URLs y los títulos de las mismas sí que van a quedar indexadas salvo que se introduzcan las etiquetas en el código
HTML de
NoIndex o se añada el
X-Robots-Tag "NoIndex" a nivel de servidor web.
 |
| Figura 2: 1.570.000 URLs indexadas en /s |
En
Dropbox el número de
URLs indexadas es de
1.570.000 sólo en el directorio
/s, lo que deja para buscar y jugar largo rato haciendo
hacking con buscadores. Hay algunas
URLs filtradas con permisos de seguridad, archivos que ya no están, pero lo cierto es que la mayoría de esas
URLs llevan a ficheros que sí que están y son accesibles, por lo que se puede sacar de todo.
Buscando así, al azar, aparecen ficheros con bases de datos de usuarios y
contraseñas, archivos comprimidos con fotografías, código fuente de
programas y aplicaciones, libros, música que se puede
buscar como hacíamos en Skydrive, películas, y casi cualquier cosa que se te ocurra.
 |
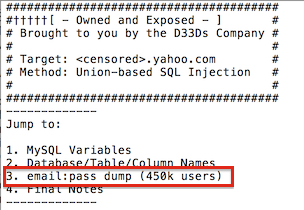
| Figura 3: Dump de 450.000 usuarios y passwords de Yahoo! |
Cuidado con Google y el robot.txt
De todo ello, lo que más me ha maravillado es cómo se puede buscar en Google información prohibida. Veréis, yo he buscado por IBAN para ver si había gente que hubiera subido datos de cuentas corrientes a Dropbox, y me ha salido un resultado donde en el título se puede ver la palabra IBAN, aunque como está protegido por robots.txt no puedo ver ningún dato del resultado.
 |
| Figura 4: Resultados con información de una cuenta corriente bancaria |
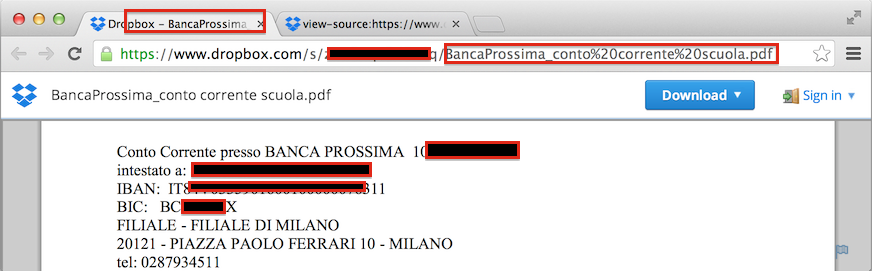
Cuando he ido a ver el sitio a ver qué se estaba compartiendo de forma
pública se puede ver que hay una página con información de una cuenta
bancaria, pero el texto IBAN solo aparece en el contenido del fichero PDF y no se encuentra en el título de la página.
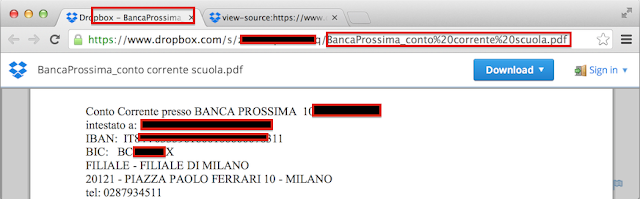 |
| Figura 5: El dato de IBAN no aparece ni en la URL ni en el título, solo en el contenido |
Mirando el código fuente a ver otra de las palabras que aparece en el título que aparece en los resultados de búsqueda de Google, la palabra CODICE, se puede ver que tampoco está allí, por lo que parece más que evidente que Google está indexando el contenido de ese documento PDF y de alguna forma dejando buscar por términos allí contenidos. Es decir, Google indexa el documento PDF, genera metadatos sobre el documento y deja buscar por ellos.
 |
| Figura 6: CODICE tampoco está en el código fuente de la página |
Además, parece que la gente de DropBox ha decidido que esto no debería estar así y en el código fuente se puede ver la etiqueta NoIndex para que Google no indexe nada del contenido de esa página web, pero o Google no le ha hecho caso aún, o esta URL estaba indexada desde antes, porque aún está en los resultados.
 |
| Figura 7: La página tiene la etiqueta noindex en el código HTML, pero está en la base de datos de Google |
A los administradores de
Dropbox les tocará darse un paseo por las
Herramientas del Webmaster e ir borrando las
URLs que ellos consideren una a una, para que no quede esto así. Si compartes algo por
Dropbox, revisa bien los permisos de seguridad y las cuentas a las que les das acceso, y ten presente que si
Google accede de alguna forma a tu
URL puede que aparezcan fugas de información en el título, los
metadatos que cree sobre el documento o la misma
URL.
Fuente http://www.elladodelmal.com
de Chema Alonso